Texto: Alberto Díaz Añel
Tradução e adaptação: Tiago Marconi
Chegou a segunda parte de nossa história! Agora vamos nos afastar um pouco de nossos conhecidos lobisomem e monstro da Lagoa Negra e vamos nos concentrar mais em como se fabrica a proteína que mais os caracteriza, a queratina de seus pelos compridos e escamas abundantes.
Em nossa publicação anterior, vimos o que são as proteínas, de que são feitas, e que a informação para fabricá-las se armazena no DNA. O fato de que os “tijolos” que são parte das proteínas (os aminoácidos) e os que conformam a estrutura do DNA (os nucleotídeos) sejam muito diferentes torna necessária uma “tradução” entre ambos.
Quem se encarrega da tradução da informação entre o DNA e as proteínas é outra molécula muito parecida com o primeiro, chamada RNA. E em quê se diferenciam o DNA e o RNA? Em primeiro lugar, como vimos em uma imagem da primeira parte de nossa história, o DNA é formado por duas cadeias que se entrelaçam uma à outra, formando o que se chama ‘dupla hélice”. À primeira vista, parece uma escada em caracol, cujos degraus são os nucleotídeos. O DNA, por sua vez, tem uma cadeia só.
Pois bem, quando há em uma cadeia de DNA um tipo de nucleotídeo, na cadeia da frente não pode estar outro qualquer, senão, devido a suas propriedades químicas, eles não poderiam se unir para dar estabilidade à dupla hélice. É por isso que os nucleotídeos estão sempre em pares. Se em uma cadeia tem um A, na da frente precisa haver necessariamente um T (e vice-versa), ao passo que, se temos um C, do outro lado precisa estar um G (e vice-versa também). Existe uma regrinha muito associada ao tango argentino para memorizar estes pares: Aníbal Troilo (AT) e Carlos Gardel (CG), famosos bandoneonista e cantor de tango, respectivamente (ambos também compositores). Para abrasileirar esse exemplo, vamos com os cantores Agnaldo Timóteo (AT) e Gal Costa (GC).
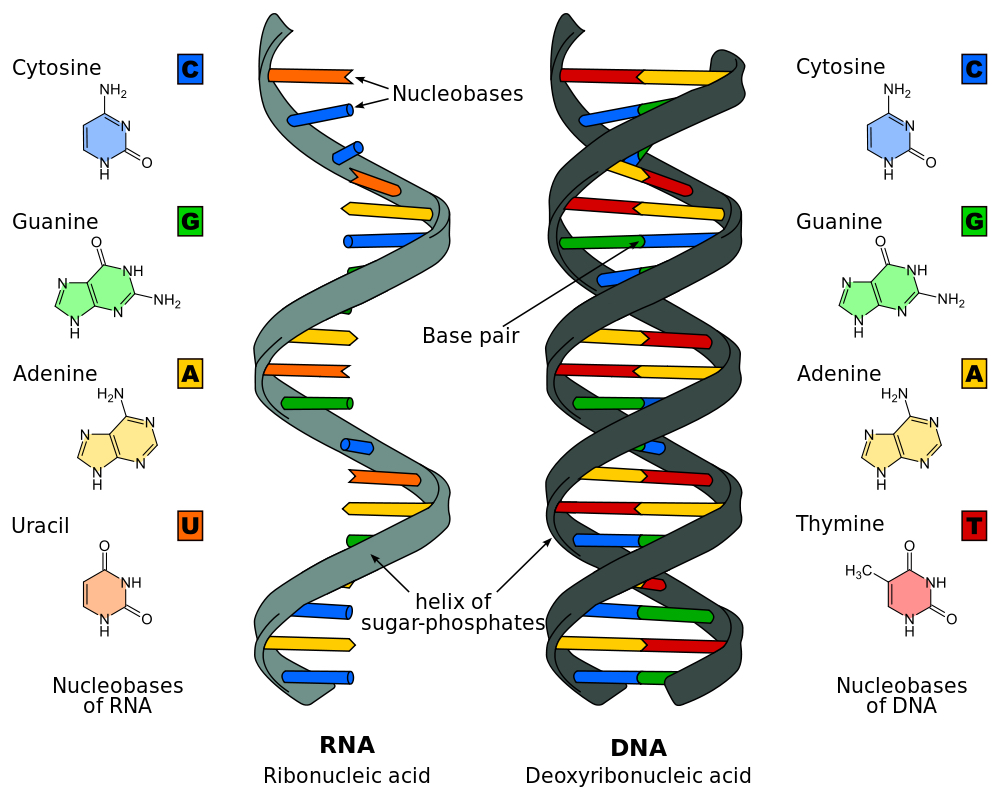
Nesta imagem podemos observar os nomes de cada nucleotídeo e o porquê de sua representação com as letras A, C, G e T – ou U no caso del RNA (imagem: Sponk – CC BY-SA 3.0)
A informação para fabricar uma proteína está em apenas uma dessas cadeias, enquanto a que fica em frente é uma sequência conhecida como complementar. Essa última é que deve ser copiada para criar a cadeia de RNA (que recebe o honroso nome de RNA mensageiro), que possuirá o código (ou seja, todos os códons) para poder fabricar uma determinada proteína. Por isso o RNA é formado por uma só cadeia, que dá e sobra para que os aminoácidos comecem a se unir na ordem estabelecida pelo código armazenado.
E por que é tão complicado, e não se traduz diretamente do DNA para a proteína? Em grande medida, isso se deve ao fato de que a cadeia dupla de DNA lhe dá uma grande estabilidade, condição absolutamente necessária para que a informação possa ser armazenada de forma segura, estável por muito tempo. É muito difícil separar as duas cadeias de DNA, e só ocorre em determinadas ocasiões, sobretudo quando o DNA se duplica (isso veremos mais adiante, com a divisão celular) ou quando se deve copiar um RNA para produzir uma proteína específica.
O RNA, em compensação, é uma molécula que não precisa se perpetuar no tempo como o DNA e que é sintetizado apenas quando necessário, já que por ter só uma cadeia está exposto a uma degradação mais rápida dentro da célula, embora às vezes formem estruturas tridimensionais complexas (alguns nucleotídeos podem se grudar e formar porções de cadeias duplas) que lhes confere maior estabilidade temporária.
Outra diferença importante entre DNA e RNA são seus nucleotídeos. Utilizam os mesmos, menos um: o T. O RNA substitui o T por um U, ou seja, uma cadeia e RNA é formada por A, C, G e U. Por isso no código genético que vimos que vimos na primeira parte da história havia um U no lugar do T. Isso significa que, quando se fabrica uma cadeia de RNA mensageiro a partir de DNA, no primeiro coloca-se um U (e não um T) quando na cadeia de DNA sendo copiada houver um A (e aí o Agnaldo TImóteo já não vale).
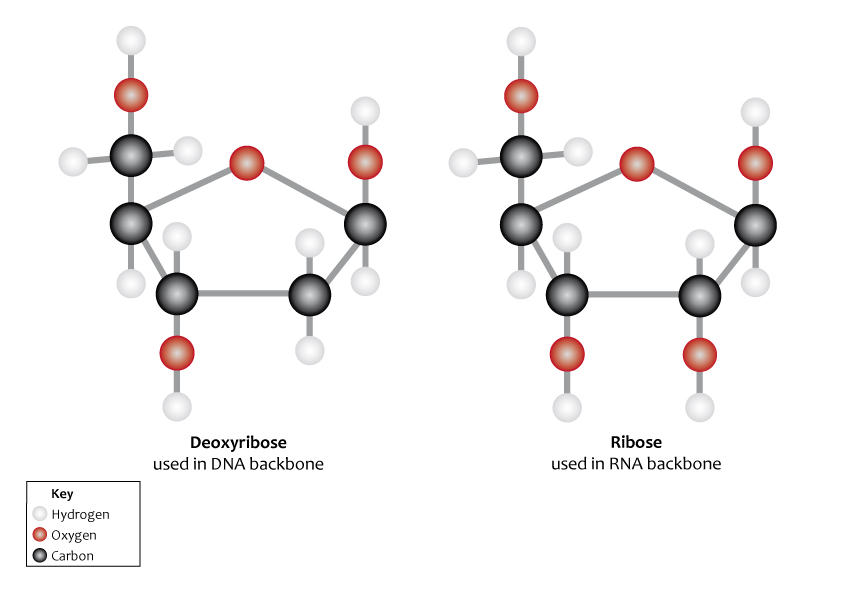
Nesta imagem, podemos ver o átomo “extra” de oxigênio na ribose (Imagem: Genomics Education Programme – CC BY 2.0)
A última diferença entre ambos tem a ver com seus nomes. Na estrutura de cada nucleotídeo existe um açúcar. No caso dos A, C, G e U do RNA, esse açúcar é a ribose. Quando esse açúcar perde um átomo de oxigênio, passa a se chamar desoxirribose (algo como “ribose sem oxigênio”), e essa faz parte dos nucletídeos do DNA, A, C, G e T. Por isso essas moléculas são conhecidas como Ácido RiboNucleico (RNA, do inglês RyboNucleic Acid) e Ácido DesoxirriboNucleico (DNA, do inglês DeoxyriboNucleic Acid).
Já sabendo as diferenças entre DNA e RNA, vamos ao que importa, a fabricação (conhecida em biologia como síntese) de proteínas. Existem determinadas regiões do DNA onde se armazena o código específico de cada proteína, por exemplo, a cadeia A da insulina ou da queratina. Uma só cadeia de DNA pode abrigar as sequências de centenas de proteínas, mas todas estão organizadas sempre em uma ordem específica. A sequência completa que codifica um tipo específico de proteína é conhecida como gene.
(Imagem: Dovelike – CC BY-SA 3.0)
Quando o corpo precisa produzir mais insulina, por exemplo quando aumenta a quantidade de açúcar no sangue, algumas células do pâncreas começam a sintetizar essa proteína através de uma maquinaria (formadas por vários tipos de proteínas diferentes) que se aproxima da sequência correspondente do DNA para abrir as duas cadeias e permitir que se comece a copiar uma delas (processo conhecido como transrição) por meio da incorporação de ribonucleotídeos (A, C, G e U, que são os que têm ribose em sua molécula), dando lugar ao que se conhece como RNA mensageiro, que, como dissemos, é de uma cadeia só e é composta pela sequência exata de códons que codificam todos os aminoácidos, nesse caso, da cadeia A da insulina. No DNA, existem sequências específicas que indicam para a maquinaria de transcrição onde começa a cópia do RNA mensageiro e onde deve terminar.
A última etapa é a verdadeira “tradução” (nome pelo qual é conhecido esse processo na biologia). Outro grupo de proteínas que forma uma estrutura conhecida como ribossomos entra em ação dentro da célula. O RNA é “enfiado” nos ribossomos e cada códon é “escaneado” pelos ribossomos. Lembram que a cadeia A começava com o códon GGC? (Na verdade, é mais complexo, mas não queremos complicar as coisas). Pois bem, o ribossomo é capaz de “ler” esse códon e permitir que outra molécula entre em cena. É outro tipo de RNA, diferente do mensageiro, conhecido como RNA transportador. Essa molécula tem forma de cruz e, em um dos extremos, possui o que se conhece como anticódon e, no outro extremo, tem um aminoácido grudado. Para o caso do códon GGC, o anticódon seria CCG (lembrem da Gal Costa), dessa forma eles podem reconhecer um ao outro. E qual seria o aminoácido que carrega o RNA transportador nesse caso? O correspondente ao códon GGC, que, como vimos antes, é a glicina.
A maquinaria de tradução pode ser vista também neste vídeo, em inglês (Imagem: LadyofHats – domínio público)
Assim, os códons vão passando um por um pelo scanner interno do ribossomo e, de acordo com a informação dos códons, cada novo aminoácido vai se encadeando aos anteriores para montar a proteína final. Como a maquinaria de tradução sabe onde parar? Se vocês olharem a tabela do código genético da primeira parte desta história, verão que em três códons (que podem ser AGU, AUG ou UGA) está escrito “STOP”, ou seja, não codificam nenhum aminoácido. Esse é o sinal para parar de traduzir. Quando aparece esse códon, a maquinaria do ribossomo se detém, não se agregam mais aminoácidos, e a proteína completa é liberada para poder cumprir sua função específica, seja baixar a glicose no sangue ou sair para combater um vírus.
E, por falar em vírus, por que dizemos que eles sequestram a maquinaria celular? Porque os vírus carregam com eles muito poucas proteínas, algumas que envolvem seu material genético e outras que funcionam como chaves para entrar na célula. No caso do Sars-CoV-2, responsável pela pandemia de covid-19, seu material genético está na forma de RNA (também existem vírus com DNA). Quando o vírus entra na célula, libera esse RNA que funcionaria diretamente como um mensageiro (por isso é conhecido como RNA+), traduzindo as proteínas essenciais do vírus para as etapas seguintes e utilizando para isso os ribossomos celulares (daí o “sequestro”).
Essas primeiras proteínas que são sintetizadas fazem parte de uma maquinaria viral que cumpre duas funções: copiar mais RNA+ para seguir fabricando todas as proteínas virais em grandes quantidades e, além disso, gerar uma cadeia complementar (chamada RNA-), que vai servir de molde para a produção de milhares de cópias extras de RNA+. Para quê? Uma vez que se termine de sintetizar os milhares de RNA+ e proteínas virais, os vírus se juntam em seu formato final, “roubam” parte das membranas internas da célula para se cobrirem e saem dela para seguir infectando, dessa vez como um numeroso exército.
Pois bem, uma das proteínas virais sintetizadas na célula infectada é chamada espícula ou proteína S, por seu nome em inglês: spike. A proteína S está localizada nas membranas que o vírus roubou da célula ao sair e, sendo a parte mais exposta do vírus, é a que ele usa para entrar nas células. Essa proteína seria como uma “chave” que é reconhecida por uma “fechadura” localizada na superfície de alguns tipos de células, como os que recobrem as vias respiratórias. A fechadura mencionada é outra proteína, conhecida como ACE2. Você podem ver o mecanismo de entrada, multiplicação e saída do Sars-CoV-2 no seguinte vídeo (em inglês e adaptado da revista Time).
Conhecer tudo isso nos serviu para o desenho de vacinas contra o Sars-CoV-2. Por quê? Porque todos os esforços estão dirigidos para que o sistema imune ataque tudo que se pareça com essa chave viral, a proteína S. Hoje, sabemos que, sendo a parte mais exposta do vírus, é a primeira coisa que o sistema imune reconhece como estranho (já vimos isso no texto sobre como o corpo se defende), portanto poderíamos desenhar uma vacina se conseguimos enganar nossa imunidade sem precisar de uma infecção viral. Como? Introduzindo somente a proteína S em nossa corrente sanguínea, obtendo assim células imunes e anticorpos contra ela sem necessidade de nos expormos ao vírus infectivo. E isso bastaria para nos defendermos de um futuro ataque real por parte do Sars-CoV-2.
E como se faz para introduzir só a proteína S? Há várias maneiras, e nelas estão baseadas as diferentes estratégias das vacinas que estão sendo desenvolvidas neste momento.
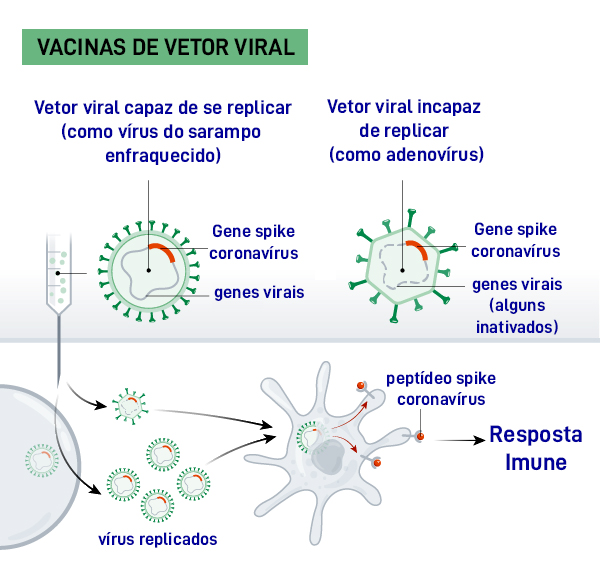
A diferença entre os dois virus que “transportam” a sequência da proteína S é que o da esquerda (sarampo ou outros) pode se multiplicar em células humanas sem causar danos, enquanto o da direita (adenovirus ou outros) não pode. (Imagem: Ciência Viva, adaptada de artigo da revista Nature)
Uma delas utiliza outros vírus (como os adenovírus) que não causam nenhum tipo de dano, já que foram previamente inativados. Seu material genético é modificado para que incorporem a sequência (o gene) que codifica a proteína S do Sars-CoV-2. Uma vez injetados esses vírus, são reconhecidos por um tipo particular de células do sistema imune conhecidas como células apresentadoras de antígenos (antígeno é a parte de uma molécula que induz uma resposta imune). Dentro dessas células se libera o RNA da proteína S e começa a síntese, usando a maquinaria celular. Essa proteína logo é exposta na superfície dessas células que, como indica seu nome, “apresentam” esse antígeno ao sistema imune, que, ao reconhecê-lo como estranho, reagirá gerando imunidade celular e de anticorpos contra essa proteína. Em outros casos, são utilizados vírus modificados não apenas para expressar a proteína S, mas também para poderem se multiplicar dentro das nossas células, mas sem causar dano (como alguns vírus de sarampo modificados). Dessa forma, podem aumentar seu número para melhorar a eficiência de “captura” por parte das células apresentadoras de antígenos. Um dos problemas desse tipo de vacinas é que uma grande parte da população poderia ter defesas contra os vírus utilizados como “transportadores” (muita gente está vacinada contra o sarampo, e algumas variantes dos adenovírus são a causa do resfriado comum), o que implicaria sua destruição antes de chegarem às células apresentadoras de antígenos. Uma das soluções para esse problema é usar vírus que infectam outras espécies e não a gente, como os adenovírus usados em uma das vacinas contra o Sars-CoV-2, que só infectam chimpanzés. A única vacina desse tipo que é utilizada é contra o vírus ebola, aprovada recentemente, em dezembro de 2019. Afora as que estão sendo desenvolvidas contra o Sars-CoV-2, estão em diferentes fases de testes clínicos outras vacinas desse tipo contra o HIV e a malária.
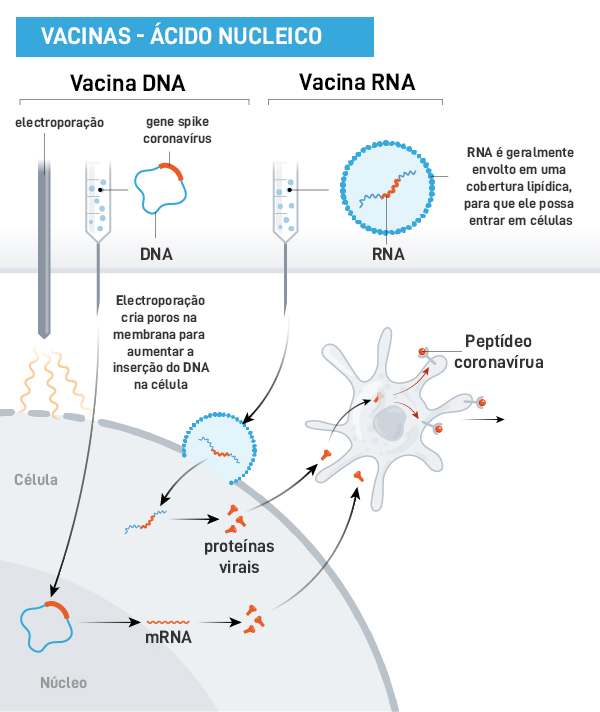
Imagem: Ciência Viva, adaptada de artigo da revista Nature
A segunda estratégia é a de introduzir no corpo diretamente o RNA+, que codifica a proteína S. Isso se consegue prendendo ele em minúsculas gotículas de vesículas formadas por lipídios (parecidas com as que envolvem o vírus, mas muito menores). Essas miniesferas vão se fundir diretamente (como fariam duas gotas de óleo) com a membrana das células apresentadoras de antígenos, onde o RNA entra e segue caminho similar ao descrito mais acima. O único problema é que, até hoje, não existe vacina realizada com esse tipo de tecnologia, por não se saber quão efetivas serão.
Na parte de baixo, a célula apresentadora de antígenos (Imagem: Ciência Viva, adaptada de artigo da revista Nature)
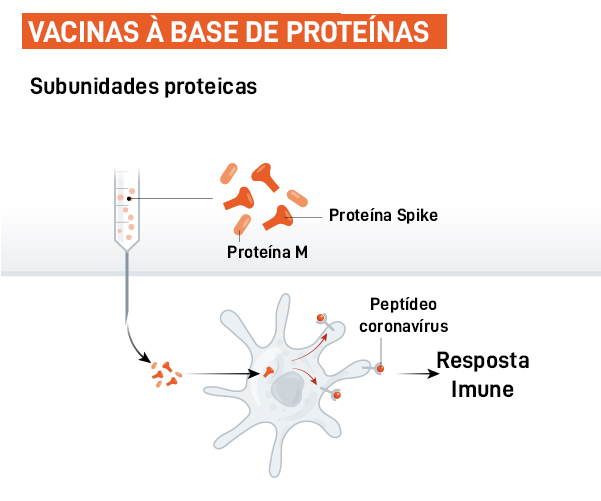
Uma terceira forma de gerar defesas é injetar diretamente partes do vírus, sobretudo aquelas que geram maior resposta imune, como seria, neste caso, a proteína S do Sars-CoV-2. Para isso, em geral, são produzidas artificialmente grandes quantidades de proteína viral, normalmente através de técnicas de engenharia genética (que permitem manipular só o gene que carrega os códons que coificam a proteína S) e de cultivo celular (que vai servir para sintetizar esta proteína em grandes quantidades). Esse tipo de enfoque foi utilizado para as vacinas contra hepatite B e contra o vírus do papiloma humano (HPV), que costumam precisar de um reforço (ou seja, uma segunda dose) para obter a resposta imune adequada.
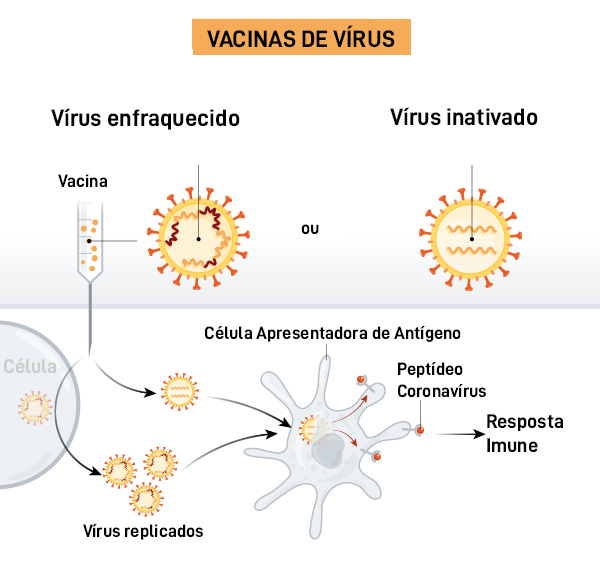
Imagem: Ciência Viva, adaptada de artigo da revista Nature
A última estratégia é a dos vírus inativados ou enfraquecidos. No primeiro caso, se utiliza o vírus completo, mas ele é inativado com altas temperaturas ou com substâncias químicas, de forma que a estrutura de suas proteínas (em especial a proteína S, que é a que mais interessa) se mantenha intacta mas o vírus deixe de ser infectivo. Inativado, ele não pode entrar na célula, por causa dos mecanismos que explicamos mais acima, e, em vez disso, é “comido” pelas células apresentadoras de antígenos. Esse é o caso de algumas das vacinas que estão sendo desenhadas contra o Sars-CoV-2, em que o RNA+ seria liberado dentro das células e traduzidos para proteínas S que vão repetir os passos das outras duas estratégias anteriores. Esse tipo de vacina já existe para hepatite A e contra o vírus da raiva. No segundo caso, os enfraquecidos, os vírus passam por uma série de processos para sofrerem mutações que os permitam multiplicar-se nas células sem causar dano a elas. Dessa forma, podem aumentar sua quantidade e, com isso, aumentar a eficiência para ativar o sistema imune, assim como acontece com os vírus inativados. Um grande número de vacinas foi criado com essa metodologia, como as que existem contra o sarampo, a cachumba, a febre amarela, a polimielite e a primeira vacina da história, que conseguiu erradicar a varíola do planeta.
No momento em que essa história foi escrita, algumas dessas vacinas se encontravam na última fase de pesquisa para que se conheça sua eficácia. Esperemos que alguma delas seja a estaca de madeira ou bala de prata que nos ajude a deter esse monstro moderno.
Ciência Monstruosa é um projeto do pesquisador e comunicador científico argentino Alberto Díaz Añel, que o Ciência na rua está adaptando para o português. Toda sexta-feira, publicamos um texto aqui e nas nossas redes sociais. Confira abaixo os já publicados.
Vampiros: quanto mais longe, melhor (publicado em 3 de julho)
Vampiros e doenças do sangue (publicado em 10 de julho)
Os lobisomens e o crescimento dos pelos (publicado em 17 de julho)
Podemos matar o que não está vivo? (publicado em 24 de julho)
Como o corpo se defende? (publicado em 31 de julho)
O essencial é invisível aos olhos (publicado em 7 de agosto)
À flor da pele (publicado em 14 de agosto)
Ciência Monstruosa: os tijolos da vida (parte 1) (publicado em 21 de agosto)



{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}