Texto: Alberto Díaz Añel
Tradução e adaptação: Tiago Marconi
Foto da home: Math / Pexels

Hotel Transilvânia (Columbia Pictures)
Apertem os cintos porque a história de hoje tem muitos matizes, então teremos que dividi-la em duas partes.
Quem viu filmes de terror (e de outros gêneros) sabe que as segundas partes nunca são boas, mas acredite: vale a pena esperar pela continuação da história de hoje, porque vai nos ajudar a compreender como o coronavírus Sars-CoV-2 se aproveita de nossas células para se multiplicar centenas de milhares de vezes. E, de quebra, também poderemos ver por que as vacinas que estão sendo feitas contra esse vírus são tão diferentes (embora todas busquem a mesma coisa).
Em nossas publicações anteriores, protagonizadas pelo lobisomem e pelo monstro da Lagoa Negra, falamos de uma proteína chamada queratina. Agora sabemos que ela está presente nas escamas, penas, chifres, cascos, garras, pelos e pele. Mas o que é e como se fabrica uma proteína?

Estrutura de um anticorpo IgG2 (Tim Vickers / Domínio Público)
As proteínas são uma parte importantíssima de nossas células e não servem apenas para cobrir nossa cabeça ou nos manter impermeáveis quando nadamos ou quando chove. São moléculas muito complexas, e é graças a essa complexidade que contamos com proteínas que possuem funções tão distintas como regular a glicose no nosso sangue (tarefa da insulina) ou nos proteger de um vírus invasivo (trabalho principal dos anticorpos). Sim, a insulina e os anticorpos são proteínas!
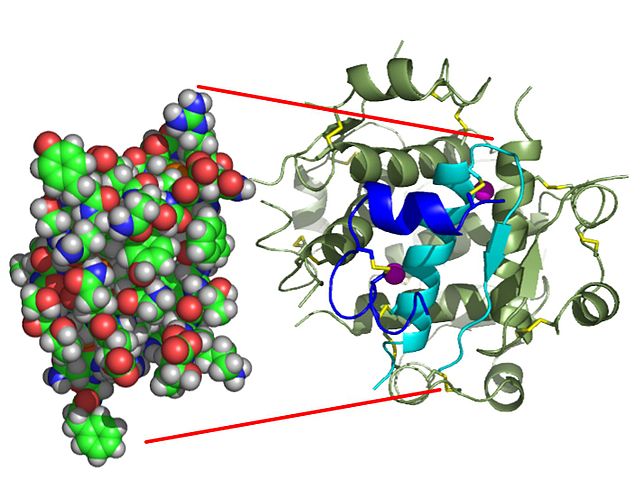
Diferentes modelos de molécula de insulina (Isaac Yonemoto – CC BY 2.5)
Agora, de que são feitas essas moléculas? As unidades que formam as longas cadeias de proteínas são chamadas aminoácidos. Basicamente, na natureza existem 20 aminoácidos, com os quais podemos contruir centenas de milhares de proteínas diferentes. É como se tivéssemos 20 tipos de tijolos com diferentes formas, e, dependendo de como os combinamos e quantos usamos de cada tipo, poderíamos construir desde uma casa até um arranha-céu – e todo tipo de edificação que existe entre uma e outro.
Por isso existem proteínas mais curtas e outras muito compridas, muitas utilizam todos os aminoácidos, e outas apenas alguns. E existem proteínas em que há grandes quantidades de um só aminoácido. Essa maleabilidade torna possível que haja tanta variabilidade, e essa variabilidade, por sua vez, permite que existam tantas proteínas com funções tão diferentes em todos os seres vivos (desde bactérias, passando por plantas, até nós) e nos vírus.
E como se constrói uma proteína? A informação sobre quantos aminoácidos serão utilizados e como serão ordenados para fabricar uma proteína se encontra armazenada em nosso DNA. Nele estão guardados essa organização e o comprimento total que cada proteína terá. Mas a maneira como se guarda a informação no DNA é bastante diferente, porque seus “tijolos”, em vez de aminoácidos, são conhecidos como nucleotídeos, que são bem diferentes entre si. E como é o processo?
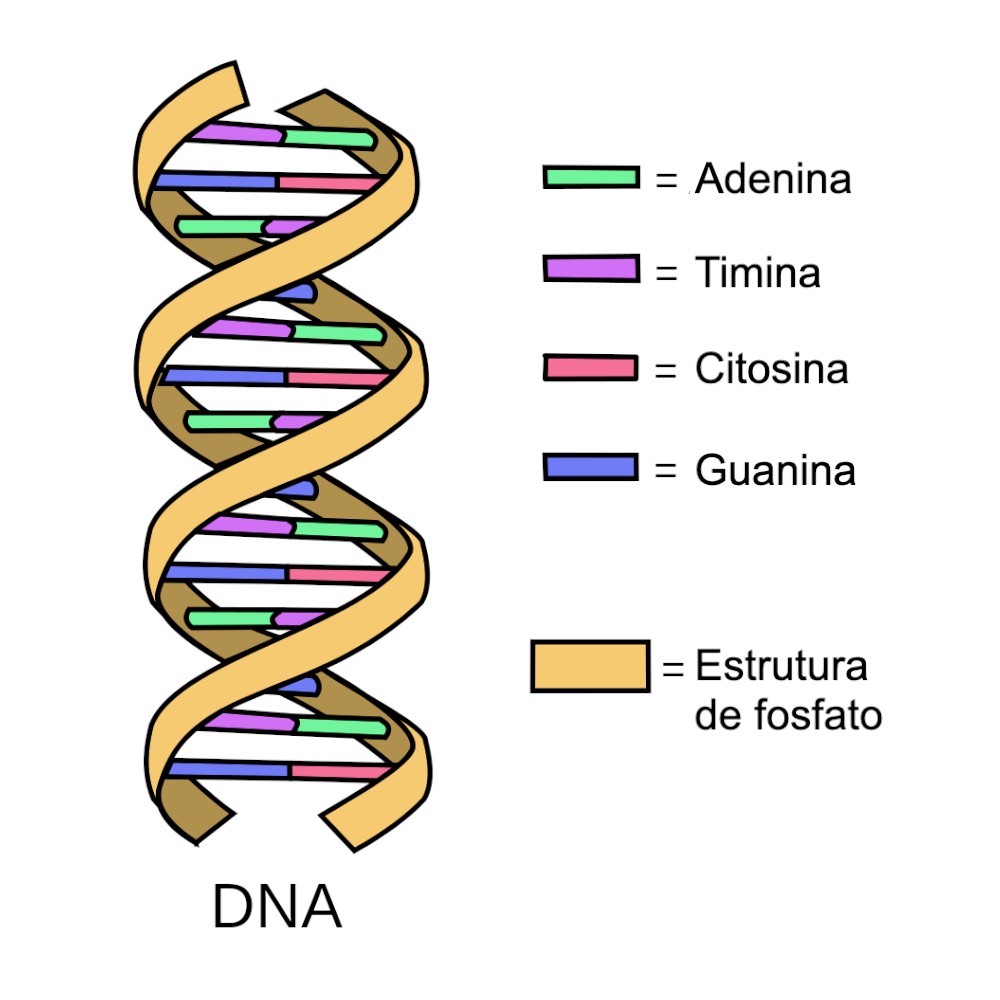
Imagem: Forluvoft / Domínio Público
Fácil (ou nem tanto). É preciso “traduzir” o idioma do DNA para o da proteína. Mas em vez de 20 (como os aminoácidos), são quatro nucleotídeos, então a coisa fica um pouco complicada para decodificar. Porém, se pensarmos em um computador, sabemos que o código binário (de zeros e uns) de um programa, combinado de certa maneira, vai indicar ao computador que mostre em nossa tela, por exemplo o caractere @ (cujo código binário é 01000000). No caso do DNA, o código seria “quaternário”, definindo-se cada nucleotídeo como A, C, G e T, que são as letras iniciais de seus nomes químicos.

No código binário do computador, temos que misturar os zeros e os uns em grupos de oito números, para obter, por exemplo, um caractere no nosso processador de texto. Para o código do DNA, é preciso misturar as quatro letras em grupos de três, o que se conhece como códon (porque cada um codifica para um aminoácido). Isso quer dizer que, se em uma sequência de DNA, leio três letras em uma determinada ordem (que pode ser de letras diferentes, como ATG, ou todas iguais, como AAA), esse códon vai corresponder a um determinado aminoácido.
Não era tão fácil, né? Vejamos um exemplo simples, a insulina. Essa molécula que regula a glicose em nosso sangue é formada, na verdade, por duas pequenas proteínas unidas entre si, conhecidas como cadeias A e B. A sequência de DNA que codifica para a cadeia A começa com o códon GGC, e essas três letras nessa ordem específica correspondem sempre a um só aminoácido, a glicina. E como sabemos isso? Porque faz 55 anos que sabemos perfeitamente qual combinação de três letras no DNA corresponde a qual aminoácido, e isso é o que chamamos de código genético.

Papai Pig, Peppa Pig (Astley Baker Davies e
Contender Group)
Finalmente, a título de exemplo, a sequência de DNA para a cadeia A de insulina tem 63 nucleotídeos, o que significa que é formada por 21 aminoácidos (63 dividido por 3), que é exatamente o comprimento que essa proteína tem em nós e em outras espécies de mamíferos. A ordem desses nucleotídeos de DNA se manteve quase intacta durante milhares de anos em várias espécies ao longo da evolução, de forma que a proteína não sofresse nenhuma mudança, já que a insulina é essencial para regular a glicose no sangue dos mamíferos, e qualquer modificação (inclusive de um só dos 21 aminoácidos en sua cadeia A) poderia significar que essa proteína já não funcione e gerar, por exemplo, diabetes. São tão similares, as insulinas entre os mamíferos, que antes de ser produzida artificialmente, os os diabéticos injetavam insulina purificada de pâncreas de porco.
Mas como não somos tão fáceis de enganar, vamos entender que se misturarmos as quatro letras do DNA (A, C, G e T) em grupos de três, teremos 64 combinações diferentes (4 x 4 x 4, ou 4 elevado ao cubo), e sabemos que só há 20 aminoácidos. E então? O que acontece é que o código genético é “redundante”. Isso significa que, para alguns aminoácidos, há mais de uma combinação de nucleotídeos possível. Temos o caso do aminoácido metionina, que só é codificado pelo códon ATG, mas também temos a serina, que pode ser codificada por seis códons diferentes (TCA, TCC, TCG, TCT, AGT y AGC).
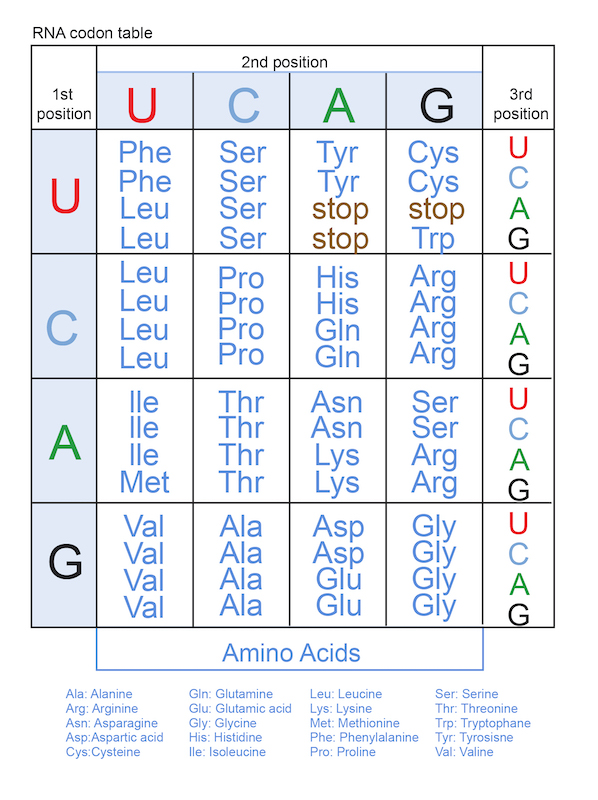
Instruções de uso para o código genético: para um determinado códon (por exemplo AAG), buscamos a letra da primeira posição (A) na coluna da esquerda (terceira fila, em verde). Em seguida, procuramos a letra da segunda posição (também A) na fila superior (terceira coluna, em verde). Por último, no quadro onde se cruzam ambas as letras (que seria o terceiro de cima para baixo e terceiro da esquerda para a direita), procuramos a letra da terceira posição (G) na última coluna (neste caso, a última letra, em cor preta). Aí veremos que o códon AAG corresponde à lisina (Lys, em inglês). ESCLARECIMENTO: A letra U é equivalente à letra T, mas isso vamos explicar na segunda parte desta história.
Bem, para concluir: a célula, que é quem se encarrega de produzir as proteínas, lê partes do DNA (por meio de – surpresa! – proteínas especialistas na leitura de DNA) e, a partir de uma sequência específica de códons, “encadeia” os aminoácidos para dar origem à proteína codificada. É, não é tão fácil! Entre o DNA e as proteínas se deve gerar outro tipo de molécula, chamada RNA, a partir da qualse traduz verdadeiramente a linguagem do DNA para a das proteínas. Mas isso vamos ver na semana que vem, na segunda parte da história, em que vamos falar de um “monstro” de nossos tempos: o coronavírus Sars-CoV-2.
Ciência Monstruosa é um projeto do pesquisador e comunicador científico argentino Alberto Díaz Añel, que o Ciência na rua está adaptando para o português. Toda sexta-feira, publicamos um texto aqui e nas nossas redes sociais. Confira abaixo os já publicados.
Vampiros: quanto mais longe, melhor (publicado em 3 de julho)
Vampiros e doenças do sangue (publicado em 10 de julho)
Os lobisomens e o crescimento dos pelos (publicado em 17 de julho)
Podemos matar o que não está vivo? (publicado em 24 de julho)
Como o corpo se defende? (publicado em 31 de julho)
O essencial é invisível aos olhos (publicado em 7 de agosto)
À flor da pele (publicado em 14 de agosto)



{kind=link}
{kind=link}
{kind=link}